Missing data is a common challenge when analyzing epidemiological data, and imputation is often used to address this issue. This talk will investigate the scenario where a covariate used in an analysis has missingness and will be imputed. There are recommendations to include the outcome from the analysis model in the imputation model for missing covariates, but it is not necessarily clear if this recommendation always holds and why this is sometimes true. We examine deterministic imputation (i.e., single imputation with a fixed value) and stochastic imputation (i.e., single or multiple imputation with random values) methods and their implications for estimating the relationship between the imputed covariate and the outcome. We mathematically demonstrate that including the outcome variable in imputation models is not just a recommendation but a requirement to achieve unbiased results when using stochastic imputation methods. Likewise, we mathematically demonstrate that including the outcome variable in imputation models when using deterministic methods is not recommended, and doing so will induce biased results. A discussion of these results along with practical advice will follow.
Missing data is a common challenge when analyzing epidemiological data, and imputation is often used to address this issue. This talk will investigate the scenario where a covariate used in an analysis has missingness and will be imputed. There are recommendations to include the outcome from the analysis model in the imputation model for missing covariates, but it is not necessarily clear if this recommendation always holds and why this is sometimes true. We examine deterministic imputation (i.e., single imputation with a fixed value) and stochastic imputation (i.e., single or multiple imputation with random values) methods and their implications for estimating the relationship between the imputed covariate and the outcome. We mathematically demonstrate that including the outcome variable in imputation models is not just a recommendation but a requirement to achieve unbiased results when using stochastic imputation methods. Moreover, we dispel common misconceptions about deterministic imputation models and demonstrate why the outcome should not be included in these models. This talk aims to bridge the gap between imputation in theory and in practice, providing mathematical derivations to explain common statistical recommendations.
Handling missing data presents a significant challenge in epidemiological data analysis, with imputation frequently employed to handle this issue. It is often advised to use the outcome variable in the imputation model for missing covariates, though the rationale of this advice is not always clear. This presentation will explore both deterministic imputation (i.e., single imputation using fixed values) and stochastic imputation (i.e., single or multiple imputation using random values) approaches and their effects on estimating the association between an imputed covariate and outcome. We will show that the inclusion of the outcome variable in imputation models is not merely a suggestion but a necessity for obtaining unbiased estimates in stochastic imputation approaches. Furthermore, we will clarify misconceptions regarding deterministic imputation models and explain why the outcome variable should be excluded from these models. The goal of this presentation is to connect theory behind imputation and its practical application, offering mathematical proofs to elucidate common statistical guidelines.
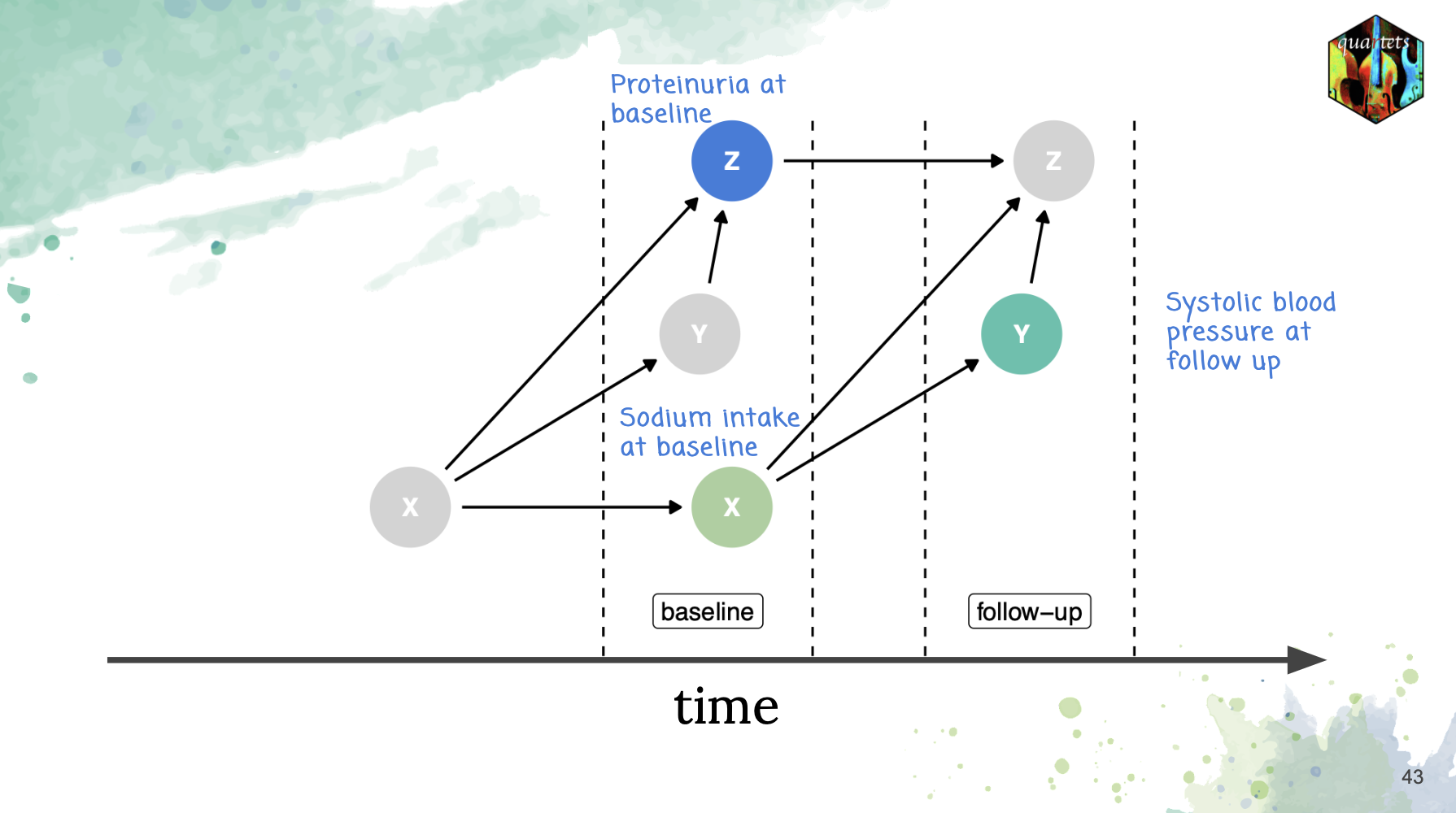
In this talk we will discuss four datasets, similar to Anscombe’s quartet, that aim to highlight the challenges involved when estimating causal effects. Each of the four datasets is generated based on a distinct causal mechanism: the first involves a collider, the second involves a confounder, the third involves a mediator, and the fourth involves the induction of M-Bias by an included factor. Despite the fact that the statistical summaries and visualizations for each dataset are identical, the true causal effect differs, and estimating it correctly requires knowledge of the data-generating mechanism. These example datasets can help practitioners gain a better understanding of the assumptions underlying causal inference methods and emphasize the importance of gathering more information beyond what can be obtained from statistical tools alone.
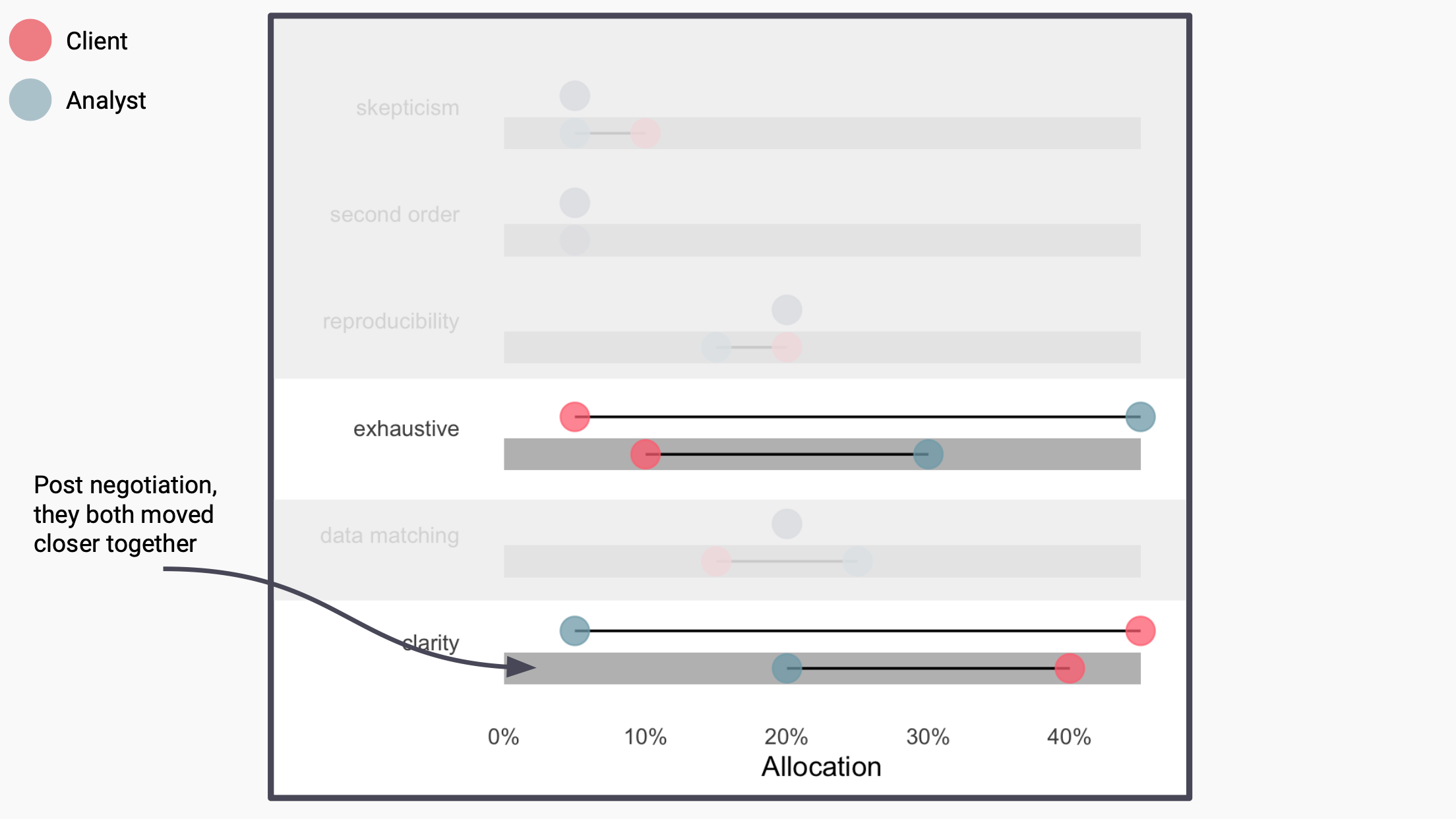
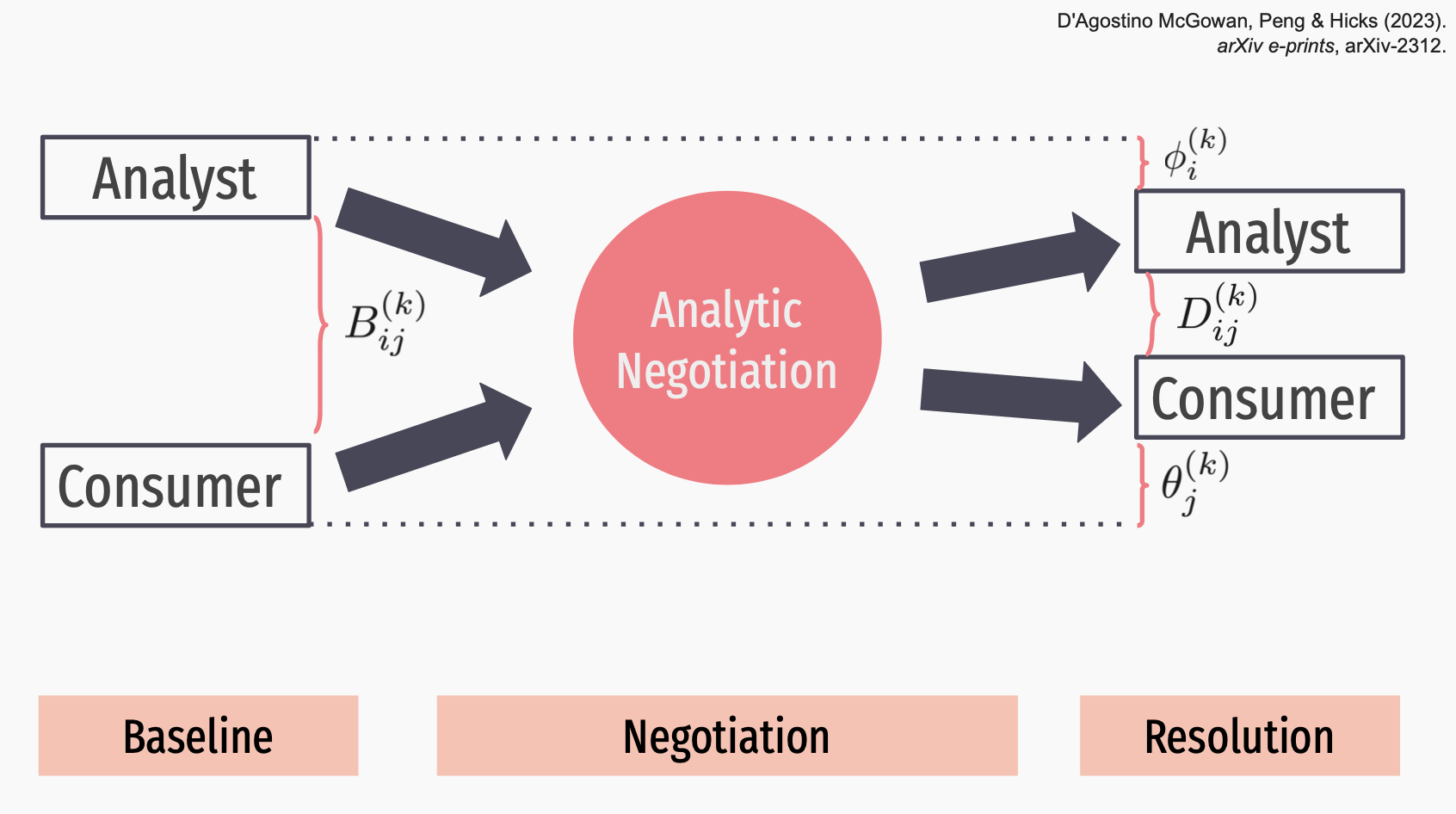
As biostatisticians, we are often tasked with collaborating on a data analysis with many stakeholders. While much has been written about statistical thinking when designing these analyses, a complementary form of thinking that appears in the practice of data analysis is design thinking – the problem-solving process to understand the people for whom a product is being designed. For a given problem, there can be significant or subtle differences in how a biostatistician (or producer of a data analysis) constructs, creates, or designs a data analysis, including differences in the choice of methods, tooling, and workflow. These choices can affect the data analysis products themselves and the experience of the consumer of the data analysis. Therefore, the role of a producer can be thought of as designing the data analysis with a set of design principles. This talk will introduce six design principles for data analysis and describe how they can be mapped to data analyses in a quantitative and informative manner. We also provide empirical evidence of variation of these principles within and between producers of data analyses. We then provide a mathematical framework for alignment between the data analysts and their audience. This will hopefully provide guidance for future work in characterizing the data analytic process.
This talk will introduce six design principles for data analysis and describe how they can be mapped to data analyses in a quantitative and informative manner. We will then introduce a mathematical framework for describing the alignment in these principles between the analyst and audience.
A data jamboree is a party of different computing tools solving the same data science problems. The NYC Open Data of 311 Service Requests contains all 311 requests of NYC from 2010 to present. This talk with demonstrate how to analyze this data using R.
The data revolution has sparked greater interest in data analysis practices. While much attention has been given to statistical thinking, another type of complementary thinking that appears in data analysis is design thinking – a problem-solving approach focused on understanding the intended users of a product. When facing a problem, differences arise in how data analysts construct data analyses, including choices in methods, tools, and workflows. These choices impact the analysis outputs and user experience. Therefore, a data analyst’s role can be seen as designing the analysis with specific principles. This webinar will introduce six design principles for data analysis and describe how they can be mapped to data analyses in a quantitative and informative manner. We also provide empirical evidence of variation of these principles within and between data analysts. This will hopefully provide guidance for future work in characterizing the data analytic process.