Miss(ing) Congeniality: The Cost of Incompatible Imputation Models
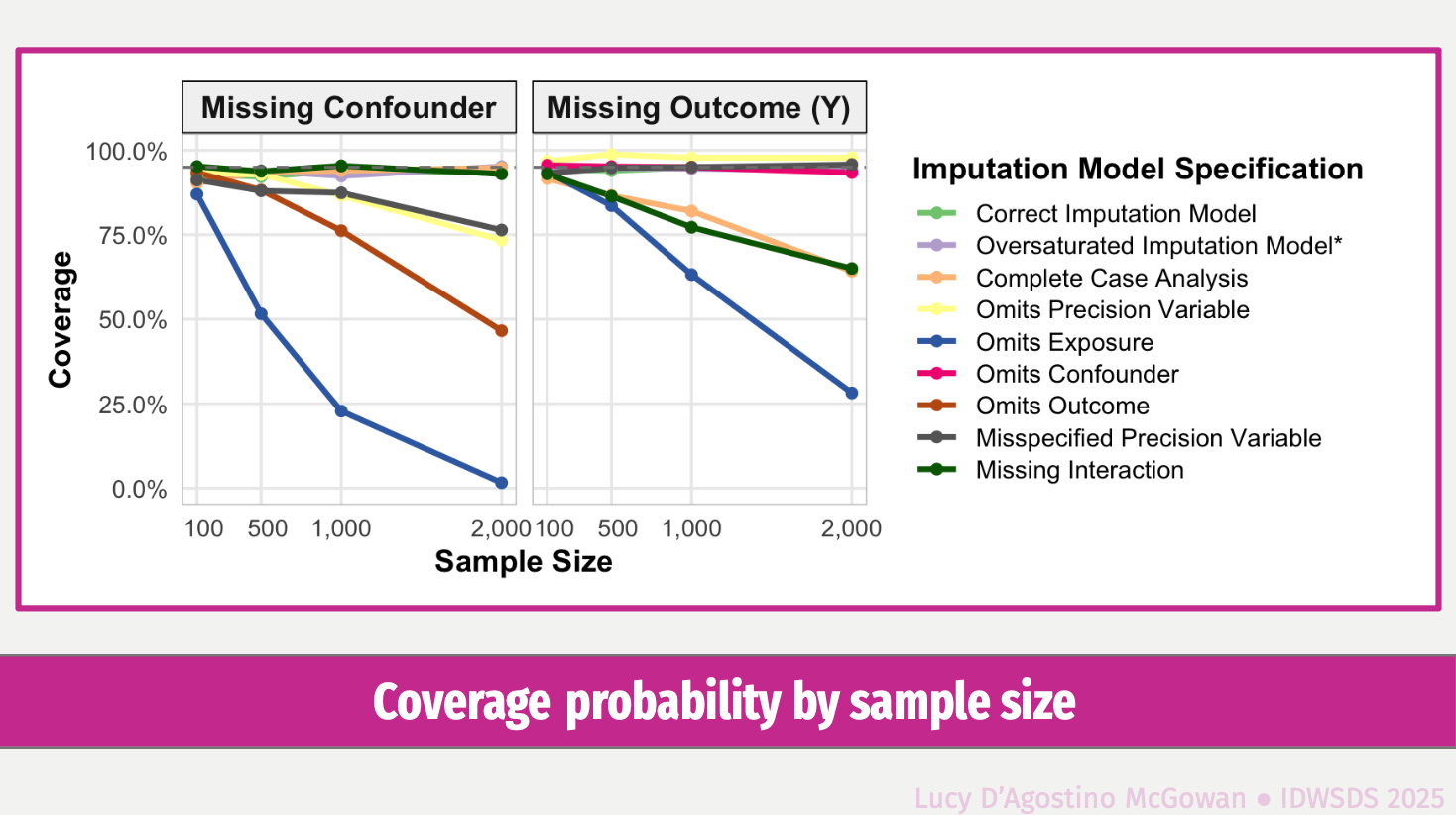
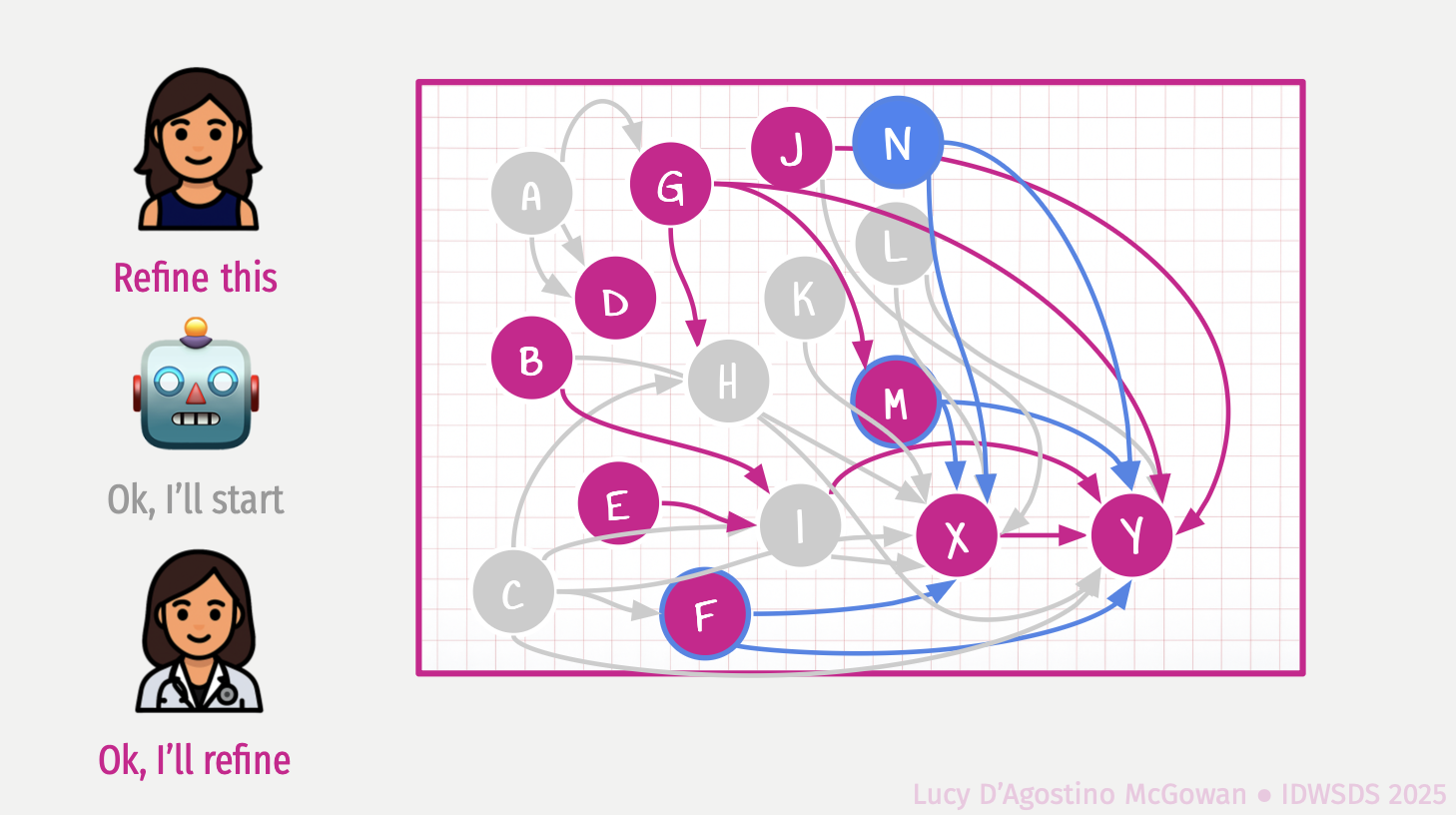
Doubly robust estimators are often viewed as protected against model misspecification, but this protection can fail in the presence of missing data. When multiple imputation is used, lack of congeniality between the imputation and analysis models can induce bias even when both the propensity score and outcome models are correctly specified. Valid inference requires imputation models to include all variables from both the propensity score and outcome models, specified in compatible functional forms. Violations of these conditions can lead to substantial bias in treatment effect estimates. A general framework for combining multiple imputation with doubly robust estimation is presented, the conditions required for congeniality are characterized, and the consequences of misspecification are illustrated. The talk concludes with practical recommendations for specifying imputation models to preserve the validity of doubly robust methods in applied causal analyses.